BigQueryを使い始めるにあたってクエリを試したりデータをロードするまでの流れをまとめました。
登録すると以下の画面になりますが、最初のプロジェクトは「My First Project」で作成されます。名前の変更はプロジェクトの管理から可能です。左側メニューのビッグデータから BigQuery に移動しましょう。
クエリの実行
クエリは毎月1TB(課金アカウントあたり)分のデータ処理まで無料で実行できます。
Pricing - BigQuery — Google Cloud Platform

左側メニューのpublicdata:samplesはすぐに使えるサンプル用のテーブルです。
実際にクエリを実行してみると次のようになります。処理に要したデータ量も合わせて表示されますが、画像ではcachedとなっています。これは、BigQuery には自動キャッシュ機能があり、同一のクエリに対しては結果を再利用することができるためです。このキャッシュ機能については使い方次第でコストを削減できそうなので詳しく調べたいと思います。

BigQuery は DELETE や UPDATE をすることができません。Redshift なんかは PostgreSQL がベースになっているだけあって、なんだかんだ普通の RDB 感覚で使えましたが、BigQuery は少し感覚が違いますね。とはいえ SELECT に関しては標準 SQL と基本的に同じなのでここはすんなり馴染めます。
Query Reference - BigQuery — Google Cloud Platform
Query Reference(日本語版)- BigQuery — Google Cloud Platform
テーブルの作成とデータのロード
BigQuery でデータをロードできるプロジェクトは、課金が有効になっているプロジェクトだけです。まずはデータセットを作成します。データセットとはテーブルの集合であり、通常の RDB でのデータベースに似たものです。
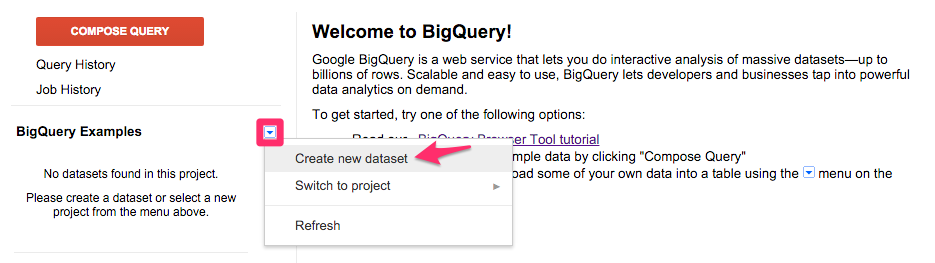
Dataset IDを入力してData locationを選択します。Expire new tables in one day.にチェックしておくと自動的に1日で削除されるようになります。データの削除を忘れると課金が発生してしまいますので、一時テーブルなどのすぐ消す予定のデータはチェックしておきましょう。
作成したデータセットにテーブルを作成します。
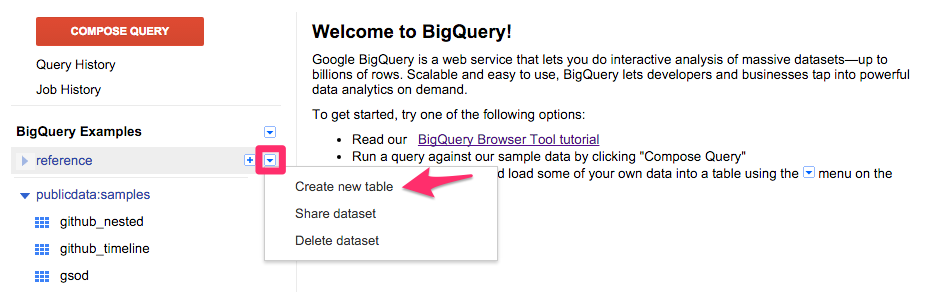
Table IDを入力して Next。
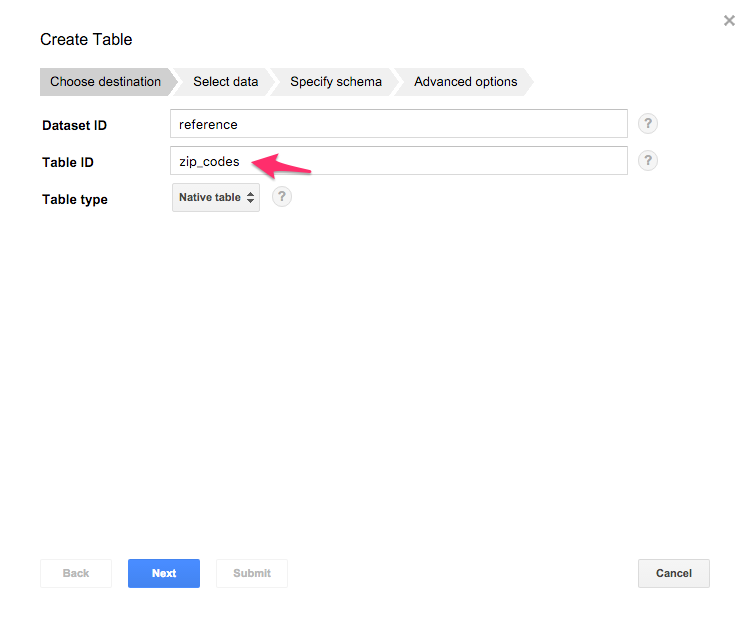
ロードするデータのフォーマットと場所を指定します。ローカルからも可能ですが、Google Cloud Storage にしました。
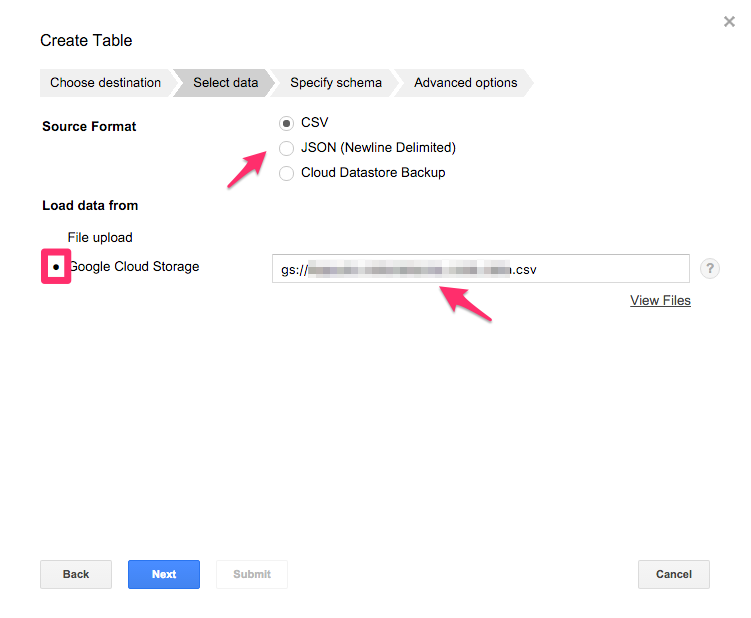
テーブルのスキーマを定義します。
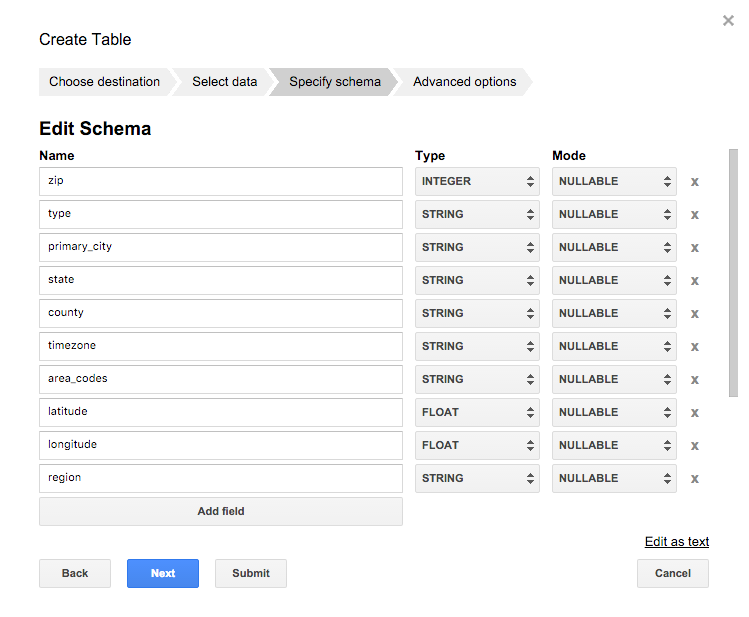
ロードに関するオプションを指定します。
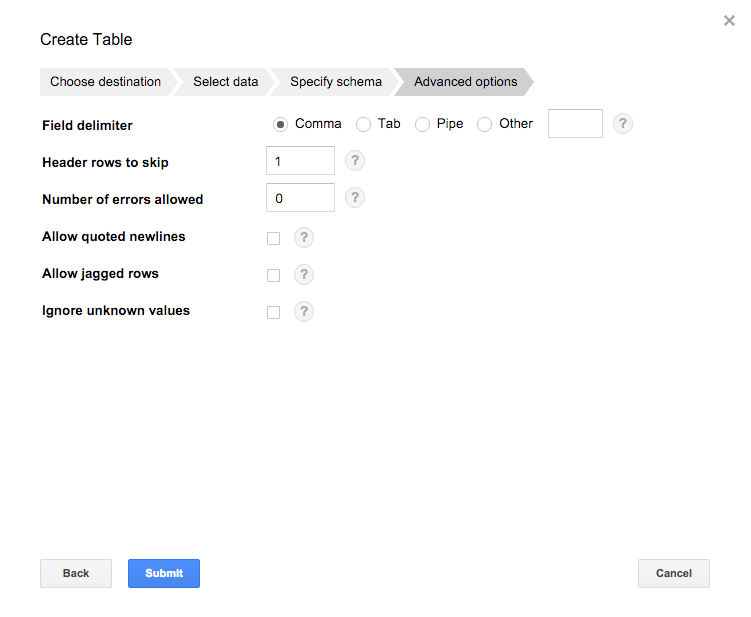
ここでのオプションは以下の通りです。
| オプション | 内容 |
|---|---|
| Field delimiter | ロードするファイルのフィールド区切り文字 |
| Header rows to skip | ヘッダーなどスキップする行数 |
| Number of errors allowed | 不正なレコードが存在した場合の許容する数 |
| Allow quoted newlines | CSVファイルの文字列項目にクォートされた改行文字を含む |
| Allow jagged rows | フィールド数よりも列が少ない場合、欠けてるフィールドは null としてロードする |
| Ignore unknown values | スキーマに一致しない値を含む行を受け入れ、不明な値は無視される |
最後 Submit をクリックするとロードが開始されます。Job History に Load の進捗が表示されるので緑色のチェックになったら完了です。

ロードしたテーブルをクリックして Details で件数やサイズ、テーブルの内容が確認できます。

参考書籍

オライリージャパン
売り上げランキング: 166,295