Resque を使用した非同期処理についてまとめました。基本は Rails での使用を想定しています。
Resqueの導入
Resque は次の3つの機能で構成されています。
- Job の作成、参照、処理のための Ruby ライブラリ
- Job を処理する Worker を開始するための Rake タスク
- Queue、Job、Worker を監視する Sinatra アプリ
Gemfile にrequire 'resque'を追加して bundle install を実行してください。Resque の Worker は永遠に動き続ける Rake タスクです。lib/tasks/resque.rakeのファイルを作成して以下の内容を記述します。
require 'resque/tasks' task "resque:setup" => :environment
rake -Tで確認するとタスクが追加されました。resque:setupをフックしてる理由は別途。
rake resque:failures:sort # Sort the 'failed' queue for the redis_multi_queue failure backend rake resque:work # Start a Resque worker rake resque:workers # Start multiple Resque workers
Resque のキューは Redis を使用して永続化されるため、あらかじめ Redis をインストールしておく必要があります。
$ brew install redis # Mac $ sudo apt-get install redis-server # Ubuntu $ redis-server # 起動
GitHub - resque/resque
Redis Quick Start – Redis
非同期処理の実行
Resque ではジョブを作成してキューに配置し、それらのジョブをキューから取り出して処理することができます。app/workers/resque_sample.rbにサンプルジョブを作成します。
class ResqueSample @queue = :resque_sample class << self def perform(message) puts message end def self.perform_async(message) Resque.enqueue(self, message) end end end
クラスメソッドに定義したperformがキューから取り出したジョブで実行されるメソッドです。内部では以下のコードで実行されるためperformがないと動きません。引数は復数指定しても大丈夫です。インスタンス変数の@queueには格納するキュー名を指定します。またはqueueというキュー名を返すクラスメソッドを定義しても大丈夫です。ジョブをキューに配置するためのメソッドはResque.enqueue(<class>, <args>)なのでクラスメソッドに定義しました。
klass, args = Resque.reserve(:file_serve) klass.perform(*args) if klass.respond_to? :perform
非同期処理を実現するために Worker を起動しておきます。正常に起動した場合は何もメッセージ等は表示されません。Redis が起動していないとエラーが出るのであらかじめredis-serverを起動しておきます。
$ QUEUE=resque_sample bundle exec rake resque:work
別タブで Rails Console を起動してジョブをキューに格納します。
$ ./bin/rails c irb(main):001:0> ResqueSample.perform_async("Hello Resque!!") => true
先程起動しておいた Worker のタブに戻るとジョブが実行されているはずです。
$ QUEUES=resque_sample bundle exec rake resque:work Hello Resque!!
Redisの設定
Redis にはデフォルトでlocalhost:6379に接続されます。環境によって接続先を分けたい場合はconfig/resque.ymlを作成して接続先を記述します。
redis: test: localhost:6379 development: localhost:6379 staging: redis.example.com:6379 production: redis.example.com:6379
次にconfig/initializers/resque.rbで作成した YAML ファイルを読み込んでResque.redisに設定すれば起動時に接続先が変更できます。
resque_config = YAML.load_file(Rails.root.join('config', 'redis.yml')) Resque.redis = resque_config['redis']["#{Rails.env}"]
Resque を複数のアプリで実行している場合などは、キースペースの名前空間が重複しないように設定することができます。
Resque.redis.namespace = "resque:task_notes"
GitHub - resque/resque: Configuration
Redisに保存されるデータ
ジョブはJSONオブジェクトとしてキューに保存されます。データを確認しやすいように Worker を起動しない状態でジョブをキューに格納してみましょう。
irb(main):001:0> ResqueDemo.perform_async("test1") => true irb(main):001:0> ResqueDemo.perform_async("test2") => true
この時あらかじめredis-cliを起動してmonitorコマンドを実行しておくとわかりやすいです。キューに格納するジョブを実行すると以下のようなコマンドが実行されて Redis にデータが格納されたのがわかります。
$ redis-cli 127.0.0.1:6379> monitor OK 1486807657.425896 [0 [::1]:54333] "sadd" "resque:task_notes:queues" "resque_sample" 1486807657.425932 [0 [::1]:54333] "rpush" "resque:task_notes:queue:resque_sample" "{\"class\":\"ResqueDemo\",\"args\":[\"test1\"]}" 1486807946.248886 [0 [::1]:54333] "sadd" "resque:task_notes:queues" "resque_sample" 1486807946.248946 [0 [::1]:54333] "rpush" "resque:task_notes:queue:resque_sample" "{\"class\":\"ResqueDemo\",\"args\":[\"test2\"]}"
Redis に格納されたデータを確認してみます。keys *でキーの一覧を確認してキーに格納されたデータを取得します。コマンドの詳細はここでは書きません。
127.0.0.1:6379> keys * 1) "resque:task_notes:queues" 2) "resque:task_notes:queue:resque_sample" 127.0.0.1:6379> SMEMBERS resque:task_notes:queues 1) "resque_sample" 127.0.0.1:6379> LRANGE resque:task_notes:queue:resque_sample 0 -1 1) "{\"class\":\"ResqueDemo\",\"args\":[\"test1\"]}" 2) "{\"class\":\"ResqueDemo\",\"args\":[\"test2\"]}"
resque_sampleのキューに格納されたデータはResque.enqueue(self, message)で指定したクラス名と引数が JSON エンコードされている状態です。この状態で Worker を起動するとキューからひとつずつデータが取り出されて処理されていきます。
$ QUEUES=resque_sample bundle exec rake resque:work test1 test2
もう一度 Redis のキューを確認するとデータが無くなっています。また、Worker を起動したことによってキーが追加されていることもわかりました。
127.0.0.1:6379> LRANGE resque:task_notes:queue:resque_sample 0 -1 (empty list or set) 127.0.0.1:6379> keys * 1) "resque:task_notes:workers:heartbeat" 2) "resque:task_notes:workers" 3) "resque:task_notes:queues" 4) "resque:task_notes:stat:processed" 5) "resque:task_notes:stat:processed:taskujp-mbp.local:47164:resque_sample" 6) "resque:task_notes:worker:tasukujp-mbp.local:47164:resque_sample:started"
Workerの起動
Resque の Worker は永遠に実行される Rake タスクです。
Worker の起動時にキューの指定をしていましたがQUEUE=*とすることですべてのキューを対象にできます。処理はアルファベット順です。また、復数のキューを指定して優先順位を指定することもできます。
QUEUES=high,low bundle exec rake resque:work
起動時にenvironmentを指定すると Rails の環境を読み込んでモデルにアクセスできます。これについては Resque というより Rake コマンドで必要なオプションです。
QUEUES=resque_sample bundle exec rake environment resque:work
このenvironmentオプションについては省略することができ、初めにも書いていましたがlib/tasks/resque.rakeに以下を追加することで実行時に自動で読み込んでくれるようになります。
task "resque:setup" => :environment
ポーリングの頻度はデフォルトだと5秒です。つまり5秒に1回 Redis のlpopコマンドが実行されてキューにデータが格納されているか確認されます。この間隔を変更したい場合はINTERVALオプションを指定して変える事が可能です。
INTERVAL=0.1 QUEUE=resque_sample bundle exec rake resque:work
ログを出力するにはconfig/initializers/resque.rbに次のような設定を追加します。
Resque.logger = Logger.new(Rails.root.join('log', "#{Rails.env}_resque.log"))
この状態で実行時にVERBOSE=1またはVVERBOSE=1の環境変数を指定するとログに記録されます。後者の方が詳細なログです。
VVERBOSE=1 QUEUES=resque_sample bundle exec rake resque:work
プロセスIDを保存するにはPIDFILEオプションを指定します。
PIDFILE=tmp/pids/resque.pid QUEUES=resque_sample bundle exec rake resque:work
PIDファイルとあわせてBACKGROUND=yesオプションを使用することで Worker の Rake タスクをバックグラウンドで実行することができます。デーモン化するなら別の方法を使った方がよさそうなのでこれはあまり使う機会はなさそうです。
PIDFILE=tmp/pids/resque.pid BACKGROUND=yes QUEUES=resque_sample bundle exec rake resque:work
ジョブの失敗
ジョブの実行中に Worker を落とした場合は<namespace>:failedというキーに失敗した情報が保存されます。ジョブのperformメソッドにsleep 10をいれて実行中に Worker を終了してみましょう。わざとundefined methodの例外を発生させるようにしても同じです。
def perform(message) puts message sleep 10 end
ジョブが失敗すると次のような情報が保存されます。
127.0.0.1:6379> LRANGE resque:task_notes:failed 0 -1 1) "{\"failed_at\":\"2017/02/12 13:33:11 JST\",\"payload\":{\"class\":\"ResqueSample\",\"args\":[\"test1\"]},\"exception\":\"Resque::DirtyExit\",\"error\":\"Child process received unhandled signal \",\"backtrace\":[],\"worker\":\"Tasuku-no-MacBook-Pro.local:65053:resque_sample\",\"queue\":\"resque_sample\"}"
allで失敗した情報を取得してrequeueでリトライできます。
詳細は resque/failure.rb あたりを参照してください。
Resque::Failure.all(0, -1) Resque::Failure.requeue(<index>)
TERM_CHILD=1の環境変数を指定すると親プロセスがSIGTERMを受け取ったときにResque::TermExceptionが投げられます。RESQUE_TERM_TIMEOUT=<sec>で指定した秒数の間に子プロセスが終了しなかったら強制終了されるため Worker 側で例外を補足して再 enqueue したりと正しくシャットダウンする必要があります。
def self.perform(key) .... rescue Resque::TermException Resque.enqueue(self, key) end
また、SIGQUITの場合は現在実行中の子プロセスの処理が全て終わってから終了されます。
Queuing in Ruby with Redis and Resque | Heroku Dev Center
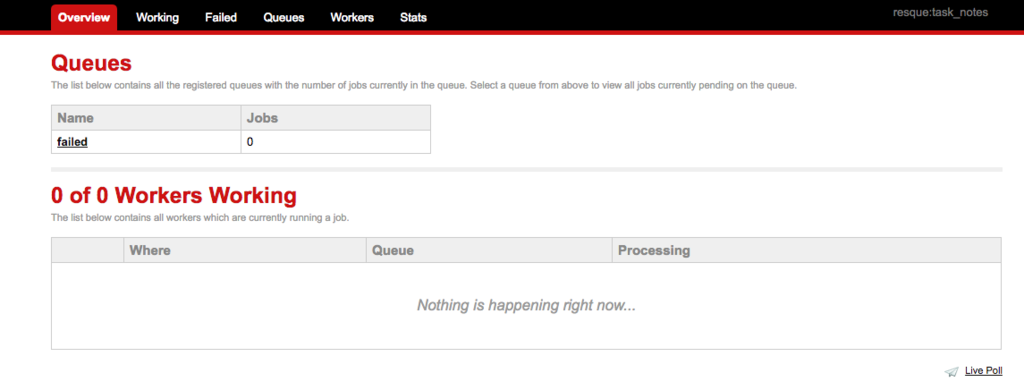
Resqueの管理画面
Resque には Sinatra ベースの管理画面があり、キューや Worker の確認ができます。使用するにはconfig/routes.rbに以下を追加してください。
require 'resque/server' Rails.application.routes.draw do ... mount Resque::Server.new, :at => "/resque" ... end
Rails を起動してhttp://localhost:3000/resqueにアクセスすると管理画面が表示されます。ここまでの使い方が理解できれば画面を見ると一通り理解できるほどシンプルです。