Amazon Redshift のクラスター作成から接続までができたら、次はテーブルを作成してデータをロードするまでを実施します。試してみたいけどデータがないという方は AWS の方でサンプルデータが用意されていますので問題ありません。この記事は Redshift 入門ガイドの ステップ 5: Amazon S3 のサンプルデータをロードする - Amazon Redshift を元にすすめています。
テーブルの作成
データをロードするためのテーブルを作成します。 ステップ 5: Amazon S3 のサンプルデータをロードする - Amazon Redshift にあるcreate table文をコピーして実行してください。今回の実行環境には SQL Workbench/J を使用しています。

Database Explorer をクリックしてテーブルが作成されたか確認しましょう。


Amazon S3からデータのコピー
テーブルの作成が完了したらデータをコピー(ロード)します。Redshift では大容量のデータをロードする場合には、Amazon Redshift SQL COPY コマンドによる S3、DynamoDB からの一括ロードが推奨されています。これは、AWS上でデータを並列に処理して Redshift にロードでき、効率が良いためです。これに比べ、INSERT クエリによる1件ずつのレコード追加はパフォーマンスが悪いです(INSERT...SELECT構文は除く)。
それでは AWS のサンプルデータを使用してロードします。COPYクエリの<region-specific-bucket-name>と<Your-Access-Key-ID>と<Your-Secret-Access-Key>を置き換えて実行しましょう。
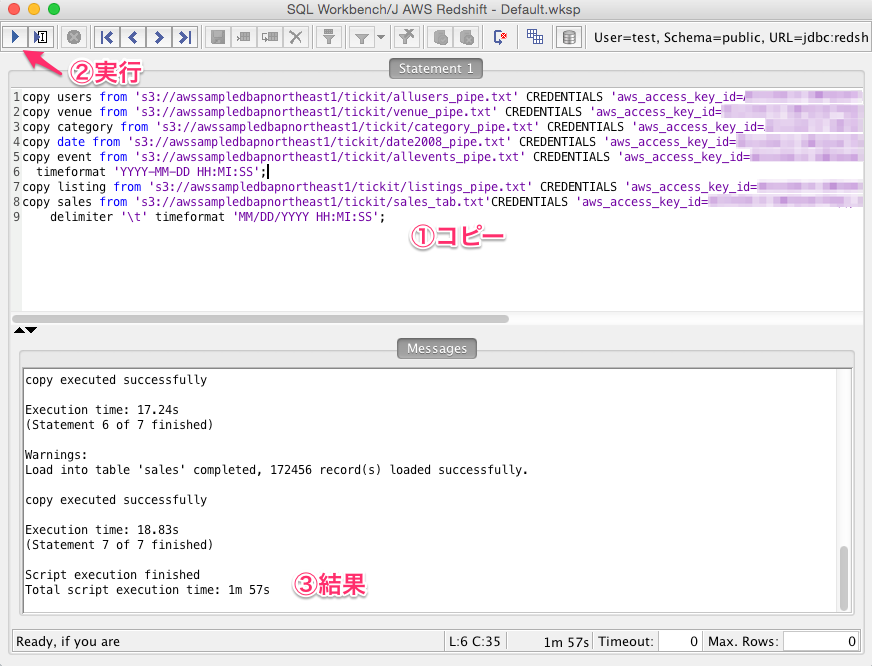
実行結果は AWS コンソールの Loads タブでも確認できます。Queries タブでも確認できますが、ロードしたクエリだけ確認したい場合は Loads タブの方が見やすいです。
クエリの実行
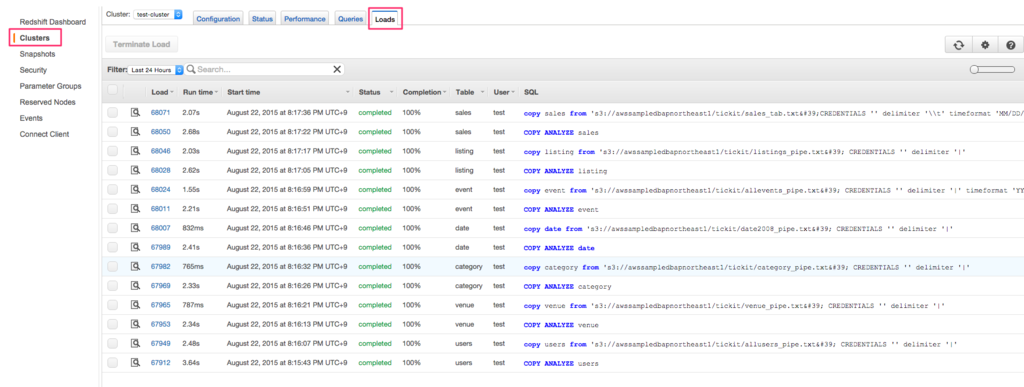
ロードしたデータに対して SQL クエリを実行してみましょう。こちらもサンプルクエリが用意されていますが、自由に SQL を書いても大丈夫です。

実行結果は AWS コンソールの Queries タブで確認できます。
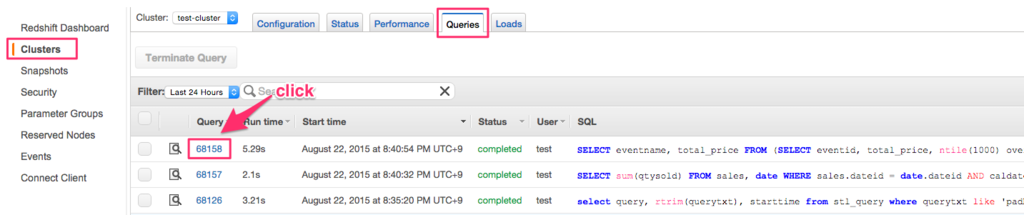
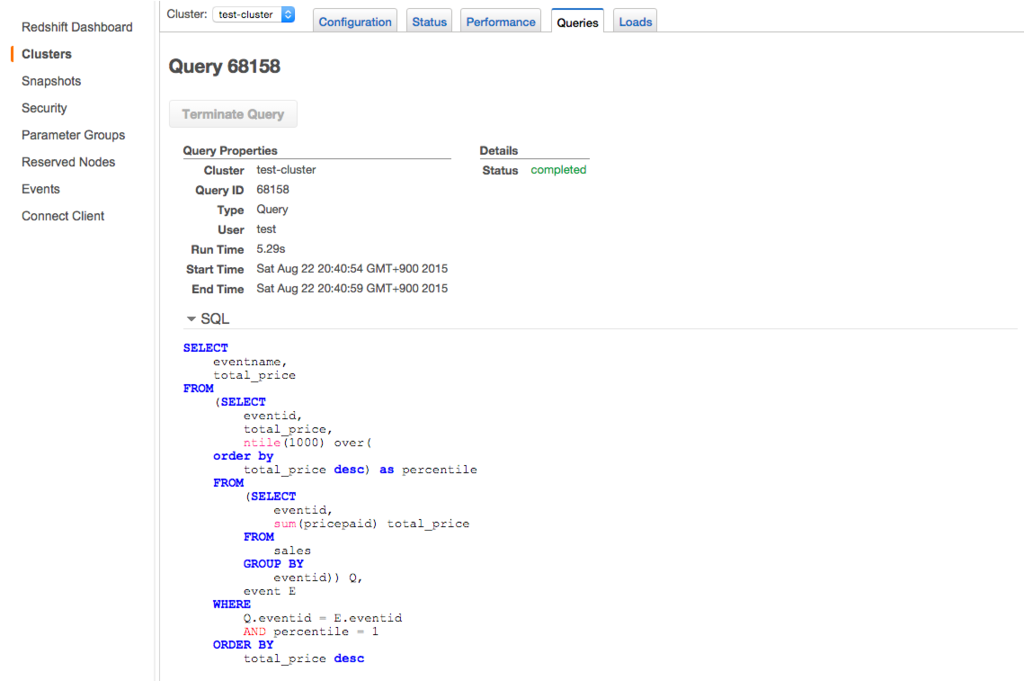
Query のリンクに移動すると詳細情報を確認できます。
まとめ
Redshift クラスターの作成から実際にデータをロードしてみるまでを試せたら、今後は以下のドキュメントを参考にして進めることになると思います。AWS はドキュメントが充実してるのがいいですよね。
Amazon Redshift の概要
Amazon Redshift 管理の概要 - Amazon Redshift
Amazon Redshift クラスタ管理ガイド
Amazon Redshift とは? - Amazon Redshift
Amazon Redshift データベース開発者ガイド
ようこそ - Amazon Redshift
関連記事
【AWS】Amazon Redshift のクラスター作成と起動から接続までの方法(入門用) - TASK NOTES
【AWS】Amazon Redshift のクラスターに接続するツールについて(SQL Workbench/J、Intellij IDEA) - TASK NOTES