前回、手動でCDHをインストールしてシングルノードのHadoopクラスタを構築する方法を書きました。今回はCloudera社が提供している QuickStartVM を使用すると、Cloudera Managerも含めた環境を簡単に使用できるようになって便利だったので、手順をまとめておきます。
ただし、これは必要なメモリが多くてかなり重いので、MapReduceを試したいだけでPC性能がよくない人(メモリ16GB理想)は前回の方法がいいと思います。
ダウンロード
Cloudera Quickstart VMをダウンロードします。この記事ではVirtualBoxでセットアップを進めていきます。(名前やメールアドレスを入力する必要あり)
QuickStart VM Download with CDH 5.4.x
ダウンロードが完了したら解凍します。しかしunzipコマンドだと~.vmdkファイルが skipping となって解凍できませんでした。
$ unzip cloudera-quickstart-vm-5.4.0-0-virtualbox.zip Archive: cloudera-quickstart-vm-5.4.0-0-virtualbox.zip skipping: cloudera-quickstart-vm-5.4.0-0-virtualbox/cloudera-quickstart-vm-5.4.0-0-virtualbox-disk1.vmdk need PK compat. v4.5 (can do v2.1) creating: cloudera-quickstart-vm-5.4.0-0-virtualbox/ inflating: cloudera-quickstart-vm-5.4.0-0-virtualbox/cloudera-quickstart-vm-5.4.0-0-virtualbox.ovf
どうやら 7zip なら解凍できるみたいなので Homebrew でインストールします。
$ brew install p7zip $ 7z e cloudera-quickstart-vm-5.4.0-0-virtualbox.zip 7-Zip [64] 9.20 Copyright (c) 1999-2010 Igor Pavlov 2010-11-18 p7zip Version 9.20 (locale=utf8,Utf16=on,HugeFiles=on,4 CPUs) Processing archive: cloudera-quickstart-vm-5.4.0-0-virtualbox.zip Extracting cloudera-quickstart-vm-5.4.0-0-virtualbox Folders: 1 Files: 2 Size: 4330709112 Compressed: 4283149641
仮想マシンの起動
ダウンロードした仮想マシンを VirtualBox で起動します。ファイルから「仮想アプライアンスのインポート」を選択して下さい。

解凍した~.ovfファイルを選択します。
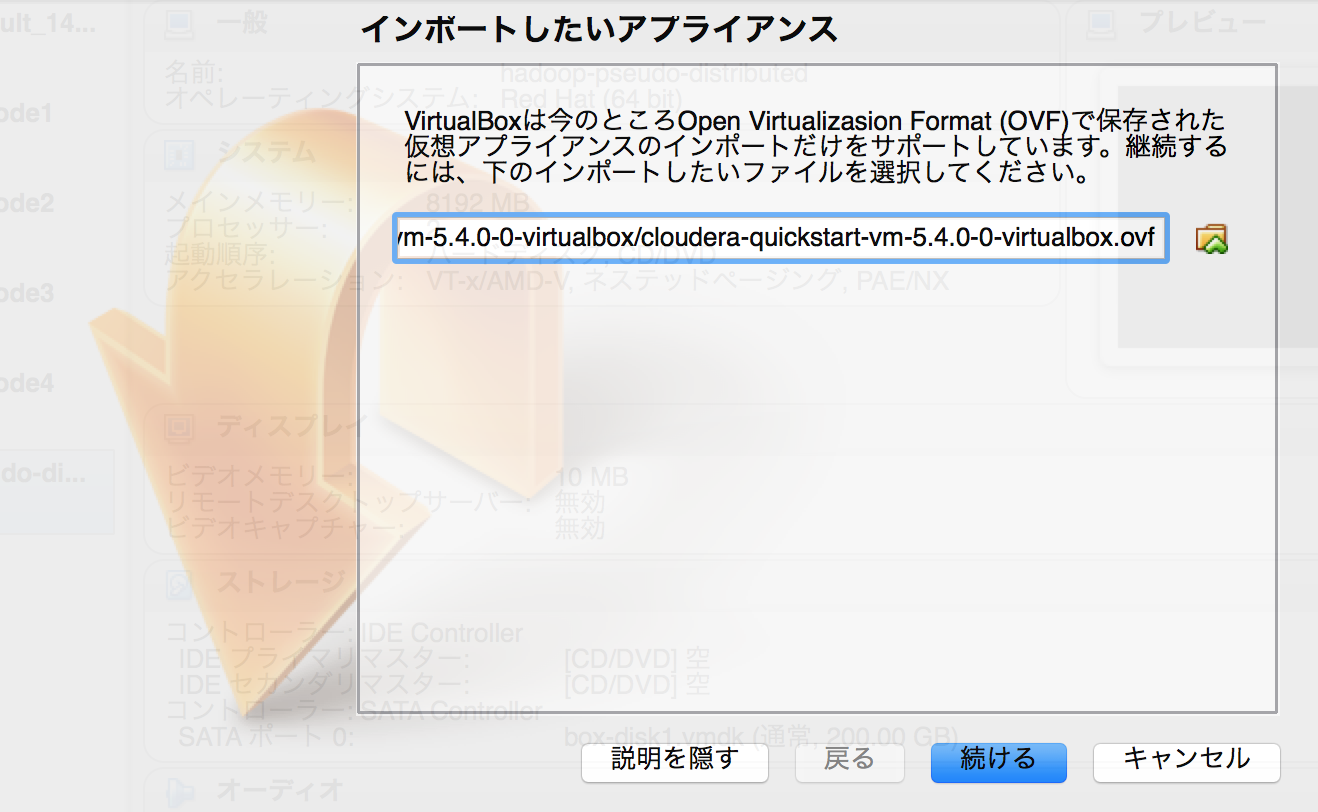
設定ではとりあえず何も変更せずにインポートを選択します。余裕があればメモリ8192MB、CPU2にしておきましょう。
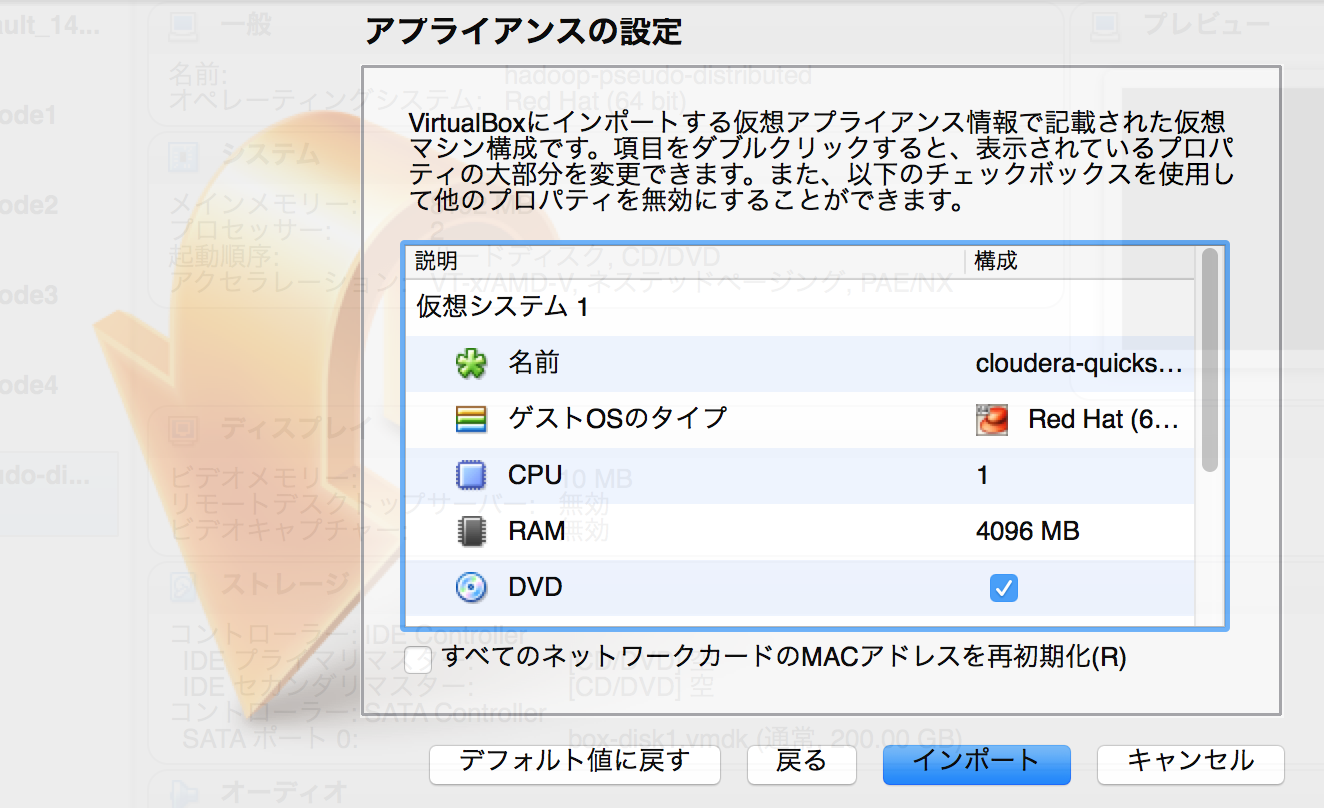
VirtualBoxに仮想マシンが作成されました。そのまま起動ボタンを押して起動させてください。途中固まったようになりますが、そこそこ時間かかるので待ちます。
起動しました。
Cloudera Managerの起動
最初に表示されてる画面を見てもどうすればいいのかよくわかりませんが、ブックマークバーにあるCloudera Managerをクリックします。
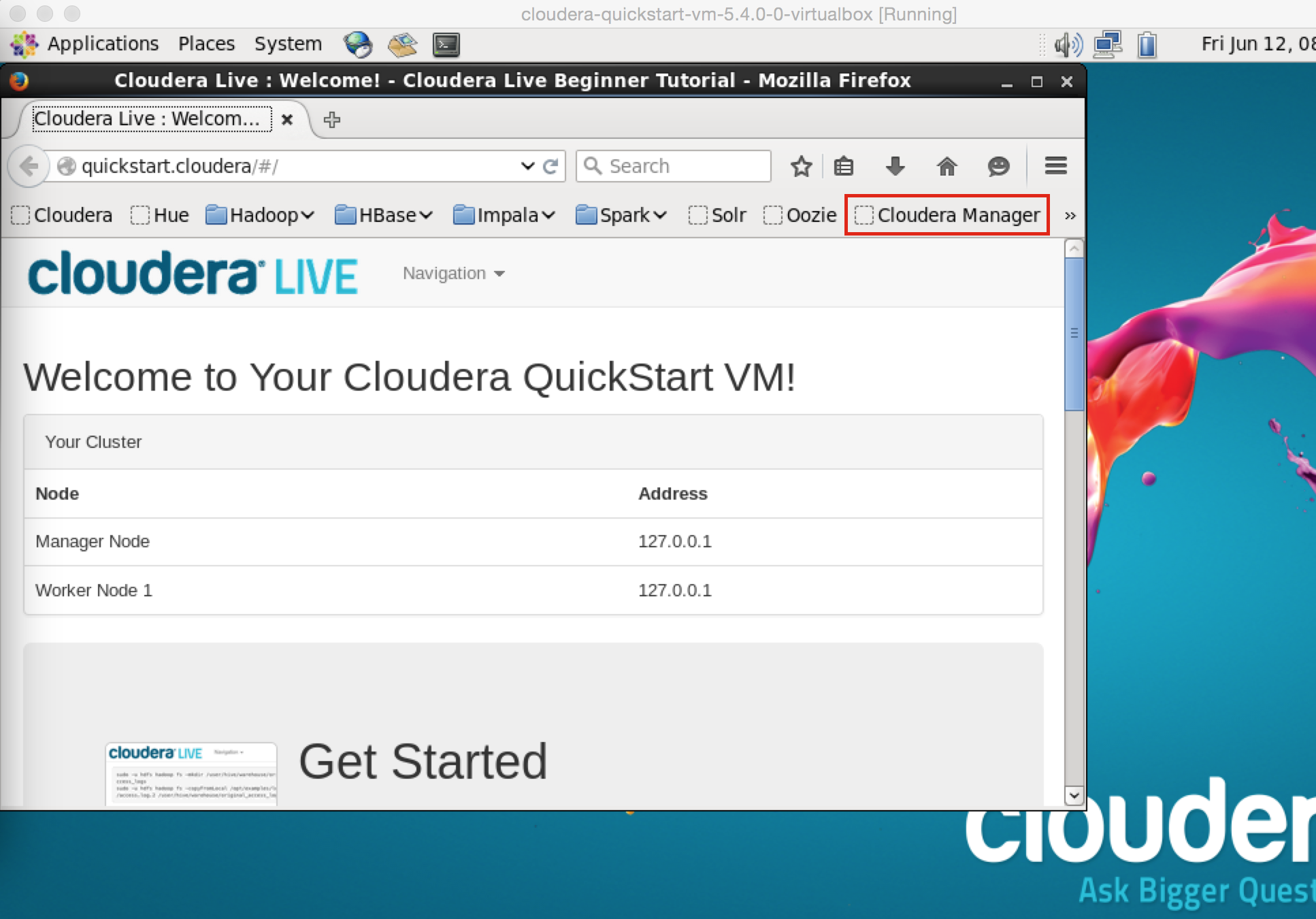
接続を試みてますというメッセージが表示されてますが、ここで待ってても起動しません。デスクトップにあるアイコンをクリックしてと表示がありますのでその通りにします。
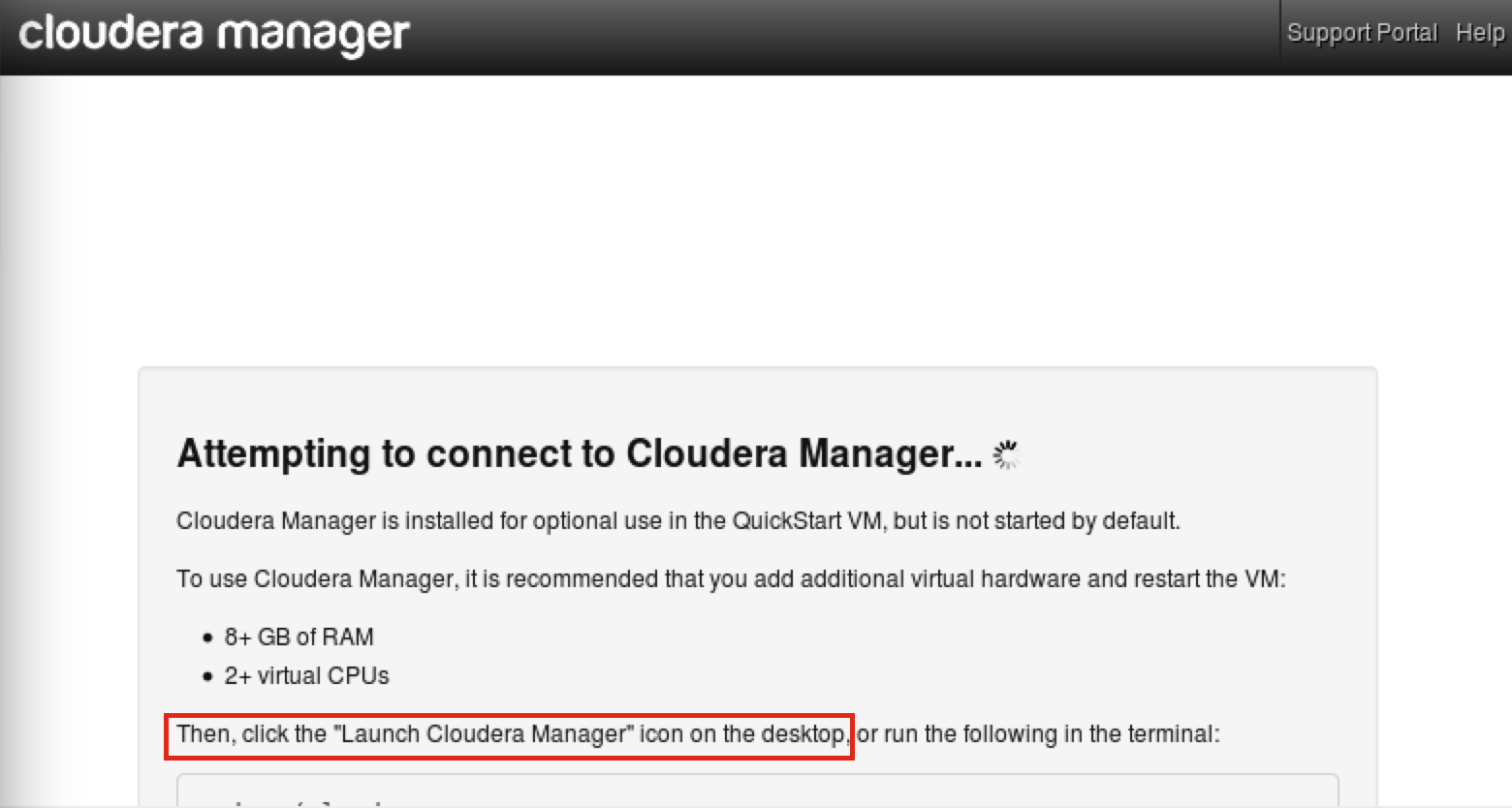
しかし、ここでもスペックが足りないので起動しません。メモリが8GB必要など書いてますが今は4GBのままでやっていきます。CPUも2つ必要みたいですね。Enter を押して画面を閉じたら、上のメニューバーにあるターミナル(黒いアイコン)をクリックして開いてください。
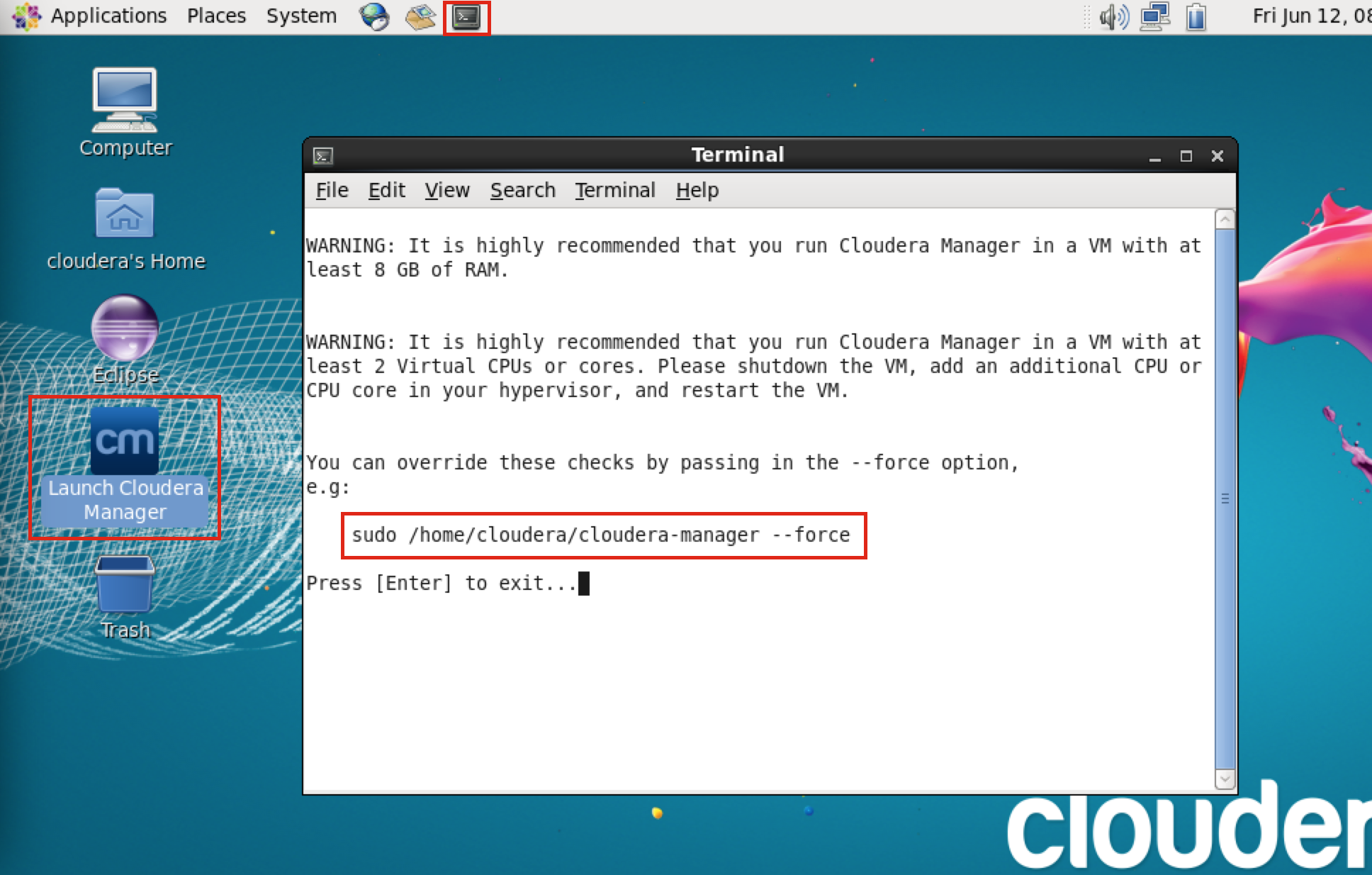
ターミナルに先程表示されていたコマンドsudo /home/cloudera/cloudera-manager --forceを打ちこみます。少し時間がかかりますが終了したら次の画面のようになります。
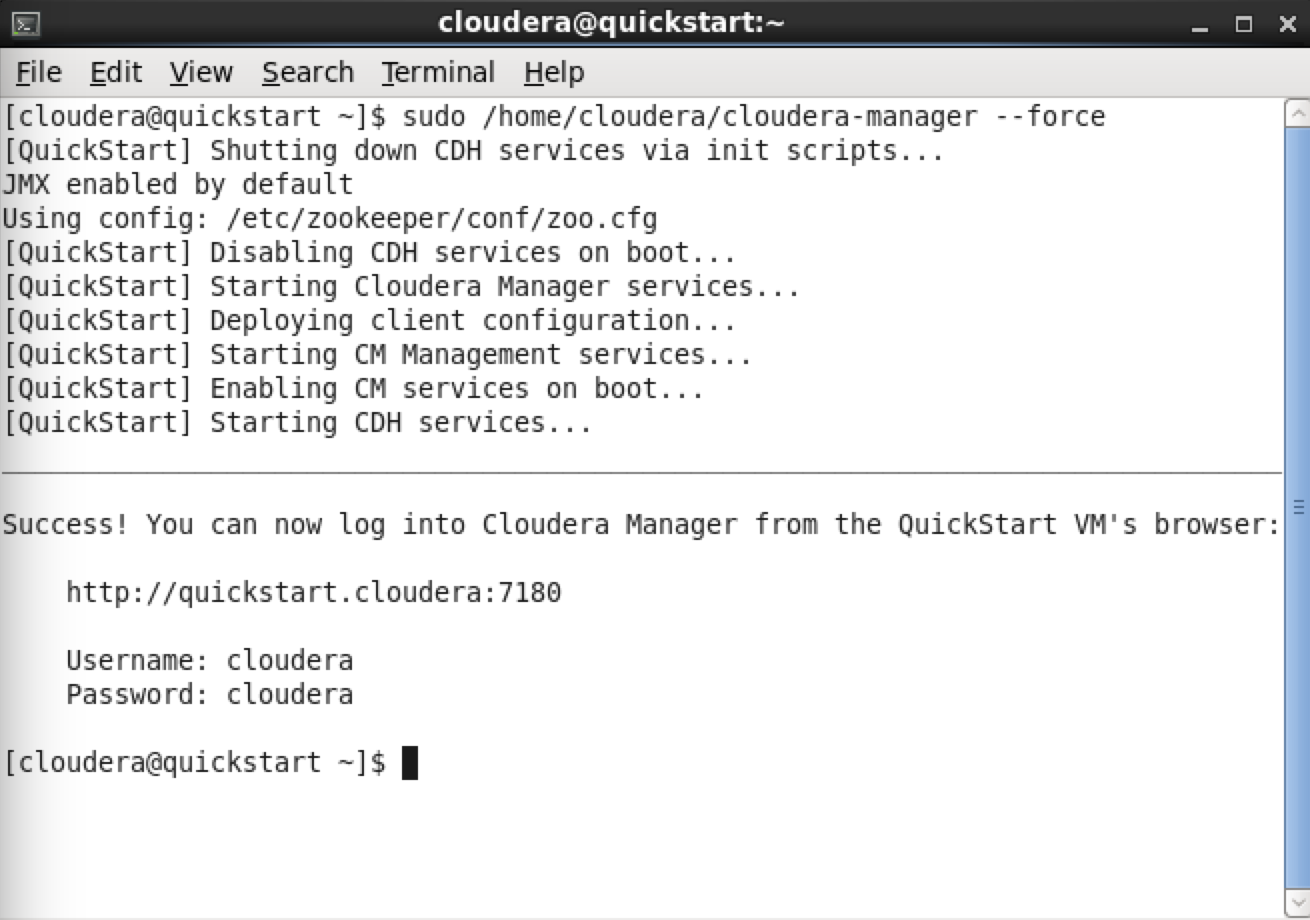
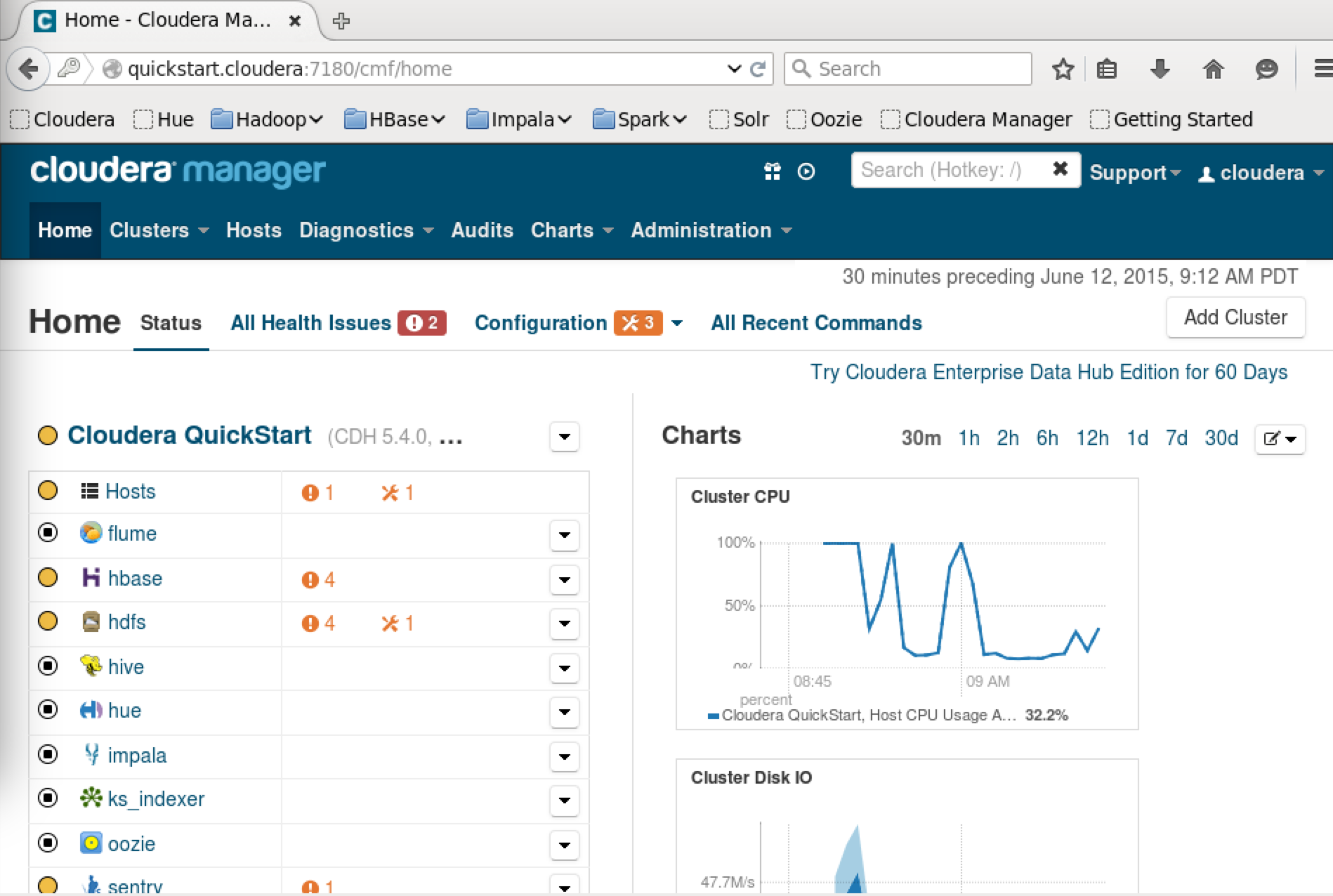
ブラウザでhttp://quickstart.cloudera:7180を開いて Username と Password を入力してログインしてください。Cloudera Manager が起動されます。と、ここで気づいたのですがキーボードがUSになってますね。
MapReduceの実行
以上でシングルノードのHadoopクラスタ(擬似分散環境)が構築されました。今回はとりあえず YARN を 使用して WordCount のサンプルプログラムだけ動かしてみましょう。
MapReduceを実行するために、停止しているYARNを起動します。
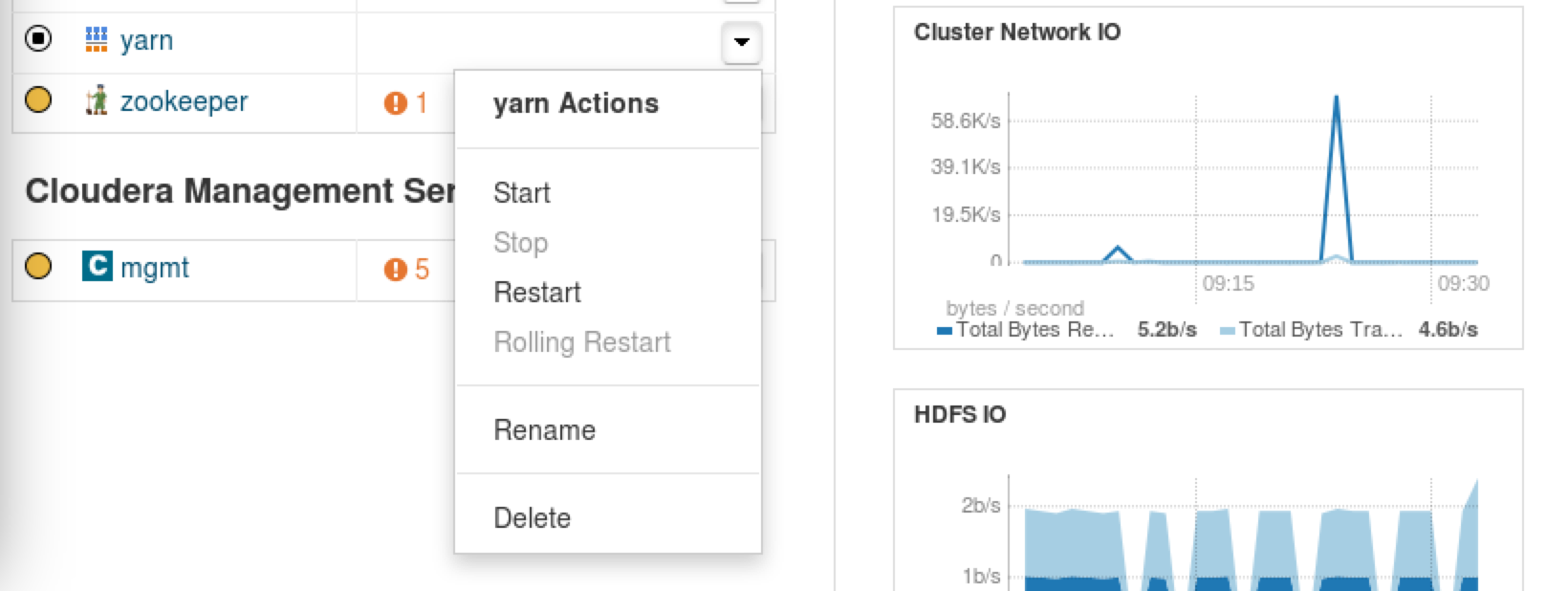
起動したらターミナルに以下のコマンドを打ち込んで下さい。
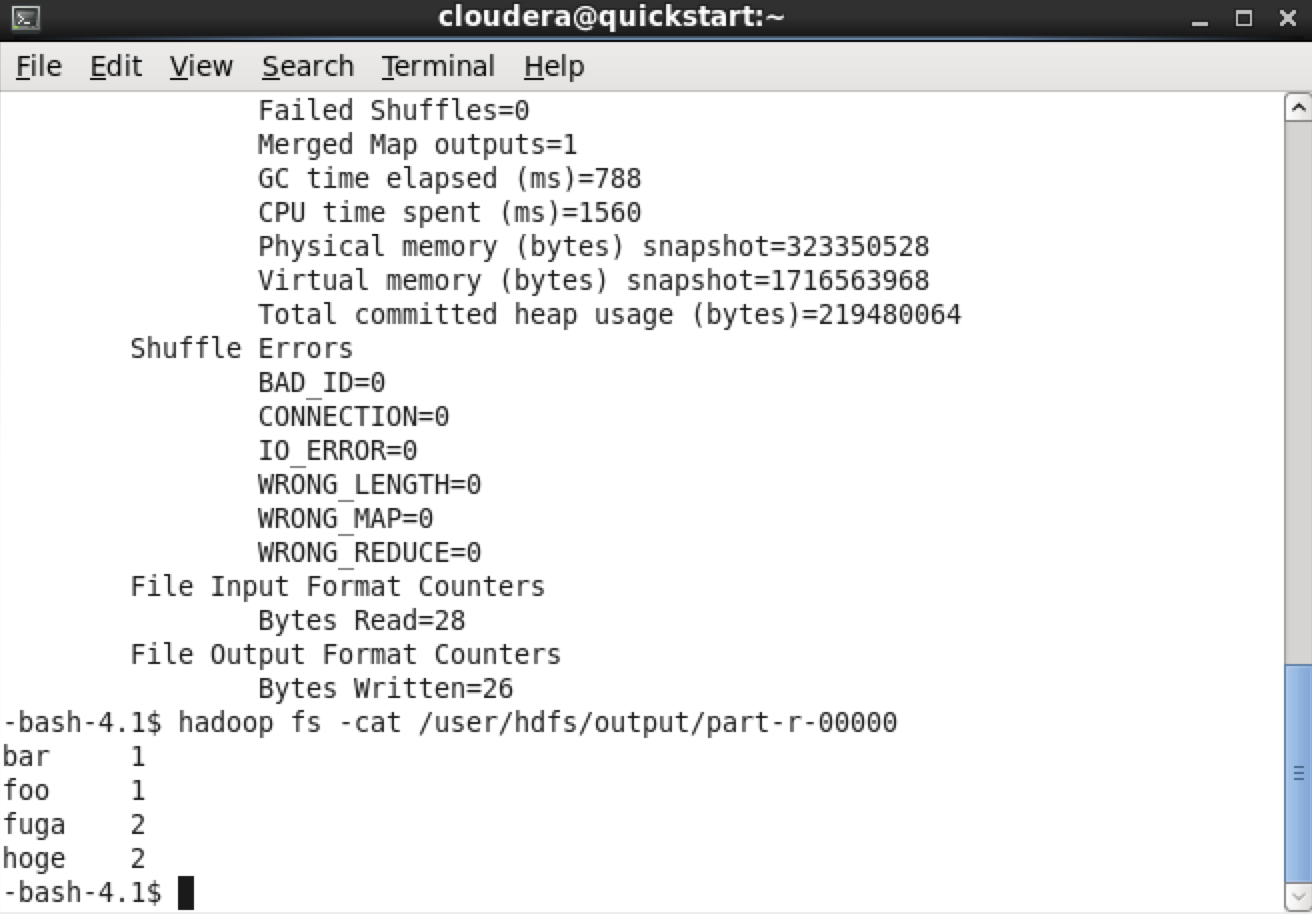
$ sudo su - hdfs $ hadoop fs -mkdir -p /user/hdfs/input $ hadoop fs -chown -R hdfs:hdfs /user/hdfs $ echo "hoge fuga bar foo hoge fuga" > wordcount.txt $ hadoop fs -copyFromLocal wordcount.txt /user/hdfs/input/ $ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-example.jar wordcount /user/hdfs/input/wordcount.txt /user/hdfs/output $ hadoop fs -cat /user/hdfs/output/part-r-00000
成功すれば完了です。
ENJOY HADOOP!